Troy Magennis: analiza Cycle Time, szybkie prognozowanie i podejmowanie decyzji.
W takcie II wojny światowej, przygotowując się do inwazji, alianci chcieli wiedzieć iloma czołgami dysponuje i ile czołgów produkuje wróg. Ale jak to obliczyć? Użyto danych, które udało się zebrać na polu walki na zniszczonych maszynach wroga w postaci analizy numerów seryjnych pancerzy, silników i kół czołgów. W ten sposób uzyskano niedużą próbkę wszystkich danych które pozwoliły oszacować ilość wyprodukowanych w lutym 44 czołgów na 270 sztuk. Jak się później okazało dokładna liczba wynosiła 276 co obrazuje jak dokładne może być prognozowanie statystyczne. Więcej o tej historii przeczytasz tutaj. Jak to się ma do analiza Cycle Time, szybkie prognozowanie i podejmowanie decyzji w Agile?
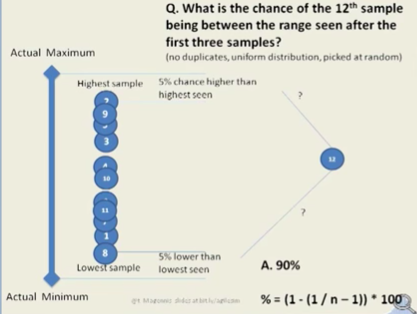
Posiadając bardzo niedużą liczbę danych wejściowych można określić prawdopodobieństwo, że jakaś kolejna wartość będzie poniżej lub powyżej dotychczas obserwowanych wartości. Dla 3 posiadanych danych to prawdopodobieństwo będzie wynosiło 50%. Przy 11 danych próbnych będzie to już 90%.
Prognozowanie w Agile
Kilka pierwszych danych jakie masz usuwa najwięcej niepewności z wykonywanych szacunków.
Nigdy nie jest tak, że prognozowanie daje jeden jedyny, prawidłowy wynik. Zawsze będzie wiele możliwych wyników z tym że niektóre będą bardziej a niektóre mniej prawdopodobne. Jest to podstawa wykonywania prawidłowego prognozowania.
Podczas trwania projektu, każda podejmowana decyzja zmienia wynik prognozy. Dlatego dobrze jest powtarzać prognozowanie za pomocą modeli tak by informacje z nich wynikające były jak najbardziej aktualne. Dla przykładu możemy wziąć pod uwagę kilka czynników: ilość osób w zespole, koszty wytworzenia oprogramowania oraz koszt opóźnienia. Zmieniając jeden z tych czynników wpływamy na pozostałe i jednocześnie na możliwy czas ukończenia prac. Rozmawiając o tym temacie jego ciężar przenosi się na dyskusję dotyczącą parametrów które mogą spowodować, że prawdopodobieństwo wykonania prac na czas jest największe.
Pracując nad nowymi projektami nie mamy danych historycznych ale możemy używać modeli, które „udają” prawdziwy świat. Dodatkowo modele pozwalają na bardzo tanie przeprowadzanie eksperymentów.
Dla przygotowania prognozy wystarczy tak na prawdę kilka podstawowych danych: data rozpoczęcia pracy nad zadaniem i data jej ukończenia zgodnie z Definition of Done. Na tej podstawie możemy obliczyć cycle time, czyli czas realizacji poszczególnych zadań, które mogą posłużyć do stworzenia prognozy dla całej funkcjonalności lub projektu. Drugą informacją którą łatwo jest zebrać to dane na temat ilości pracy w toku w danym okresie czasu (WIP).
Monte Carlo i Agile
W celu przeprowadzenia prognozy używa się modelu Monte Carlo, który pozwala na obliczenie, przedstawienie różnych scenariuszy i prawdopodobieństwa ich zaistnienia. Przeprowadzenie tysiąca takich symulacji pozwala na określenie z jakim prawdopodobieństwem jak długi będzie cycle time, czyli kiedy będziemy w stanie dostarczyć daną pracę przy danym poziomie pewności.
Patrząc na uzyskane modele możemy rozmawiać o bardziej konkretnych rzeczach. Daje to możliwość pytania zespołu: „Co może pójść nie tak?”. „Co może uniemożliwić nam dostarczenie?” – „Ile więcej pracy potrzebujemy w takim przypadku?”. Przeniesienie rozmowy na koszt opóźnienia pozwala pokazać jakie będą negatywne skutki poźniejszego niż potrzeba biznesowa dostarczenia. Dzięki tej wartości zmienia się również rozmowa, ponieważ jeżeli np. mamy do stracenia milion dolarów, to łatwo stwierdzić, że np. zwiększenie zespołu będzie kosztować mniej niż ten milion.
W Scrumie, na koniec każdego sprintu resetujesz niepewności występujące w projekcie ponieważ masz wiedzę, ile zadań zostało wykonanych. W Kanbanie odbywa się to przy skończeniu każdej historyjki i każdego zadania. Dlatego właśnie z każdą nową porcją danych powinniśmy ponownie sprawdzić jak kształtuje się przygotowany przez nas model.
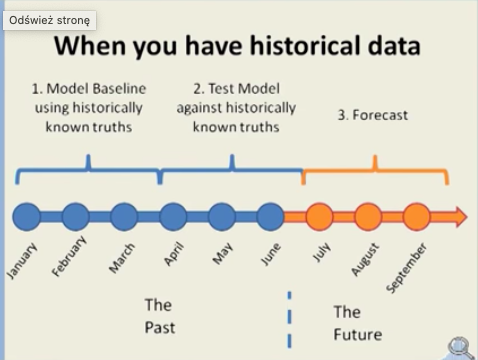
Przygotuj model i sprawdź go po np. 3 miesiącach pracy aby stwierdzić jak dobry jest twój model. Na tej podstawie możesz dokonać niezbędnych korekt i dalej prognozować przyszłe wartości. Weryfikacja modelu pozwala na naukę i zmniejszenie niepewności. Jeżeli model okazuje się różny od rzeczywistości, można zapytać dlaczego. Można przeanalizować sytuację co spowodowało, że model nie pasuje. Posiadanie modelu, któremu można zaufać, daje możliwości przeprowadzania tych eksperymentów, odkrywania różnych czynników i i ich wpływu na projekt.
Przeczytaj również notatkę z innego wystąpienia Troya, która uzupełni Twoją wiedzę na ten temat.
Oryginalna prezentacja wystąpienie
Sama pełna prezentacja: